Deployments vs StatefulSets in Kubernetes
Let’s explore the key differences between Deployments and StatefulSets, and learn why headless services are essential for stateful applications.
What is Deployment?
- In Kubernetes, a “Deployment” is an object that provides declarative updates and management for a set of replica pods.
- When creating a Deployment, you define the desired state, which includes container images, replica counts, and other configurations.
- Kubernetes then ensures that the actual state matches the desired state.
- If there are dissimilarities, Kubernetes automatically takes action to reconcile the state, creating or deleting pods as necessary.

Key Features of a Deployment
1. Automated Rollouts and Rollbacks:
You can deploy a new app version, and Kubernetes will gradually roll out updates, ensuring minimal downtime. If there’s an issue, it can roll back to a previous version.
2. Self-healing:
Deployments automatically replace failed or unresponsive pods to keep the application running as expected.
3. Scaling:
Easily scale the number of replicas (instances) up or down based on demand.
4. Declarative Updates:
You specify the desired state (like the number of replicas, container images, etc.) in a YAML file, and Kubernetes works to maintain that state.
Example Use Cases
1. Web servers
2. REST APIs
3. Frontend applications that don’t need persistent storage
How Does It Work?
A Deployment uses a ReplicaSet to ensure the desired number of pod replicas are running. If a pod fails or is removed, the ReplicaSet will create a new one to match the desired state specified in the Deployment configuration.
Example:

What is a Statefulset?
- StatefulSets in Kubernetes are workload API objects used to manage stateful applications.
- Unlike the traditional deployment of stateless applications, stateful applications require stable and unique network identities, stable storage, and ordered and predictable deployment and scaling.
- Statefulsets are commonly used for deploying and managing stateful applications such as databases(e.g., MySQL, PostgreSQL), messaging systems, and other applications that require stable network identities and persistent storage.

Here are some key features and characteristics of Statefulsets
1. Stable network identities:
Each pod in a Statefulset is assigned a unique and stable hostname based on the defined naming convention. This allows stateful applications to have a consistent network identity even when they are scaled up or down
2. Ordered deployment and scaling:
Statefulsets ensure that pods are deployed and scaled in a sequential and orderly manner. Each pod is created and fully running before the next pod is started, ensuring dependencies and sequencing requirements are maintained.
3. Stable storage:
Statefulsets provide stable and unique storage volumes for each pod. Persistent volumes(PVs) and Persistent volume claims(PVCs) are used to provide storage to the pods, allowing data to be persisted and retained across pod restarts and rescheduling.
4. Headless service:
Statefulsets automatically create a Headless service, allowing each pod to have its own DNS entry. This enables direct communication between pods using their unique hostnames.
5. Stateful pod scaling:
Statefulsets support both vertical and horizontal scaling. Vertical scaling involves changing the resources (CPU and memory) allocated to each pod, while horizontal scaling involves adding or removing pods from the StatefulSet.
6. Ordered Termination:
When scaling down or terminating pods in a StatefulSet, Kubernetes ensures that the pods are terminated in the reverse order of their creation. This allows for orderly application shutdowns and ensures data integrity and consistency.
How is data replicating and What is Data replication?
- Since each pod in the StatefulSet has its own PV and PVC, data replication can be handled at the storage level.
- Many cloud-based storage solutions, like Amazon Elastic Block Store (EBS), provide data replication capabilities to ensure high availability and data integrity.
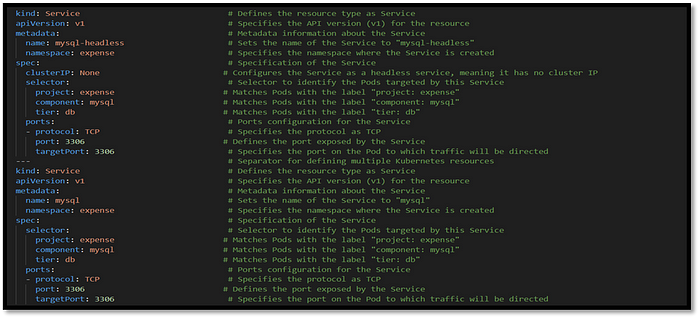
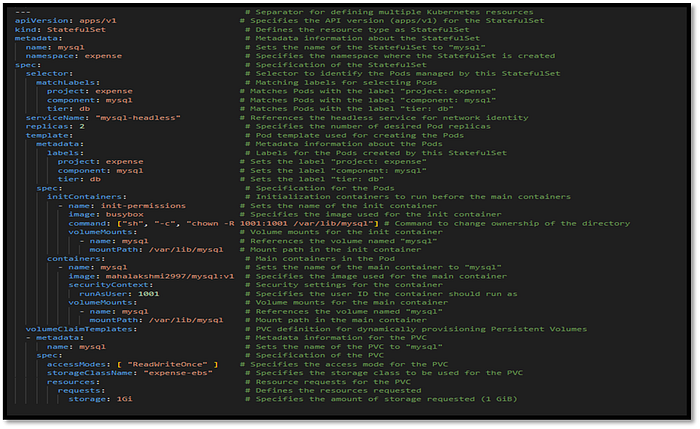
Why do we need headless service?
- A headless service in Kubernetes is used with StatefulSets to provide each pod with a unique, stable network identity and allow direct access without load balancing. This is essential for stateful applications like databases, where each instance needs a consistent hostname and direct communication.
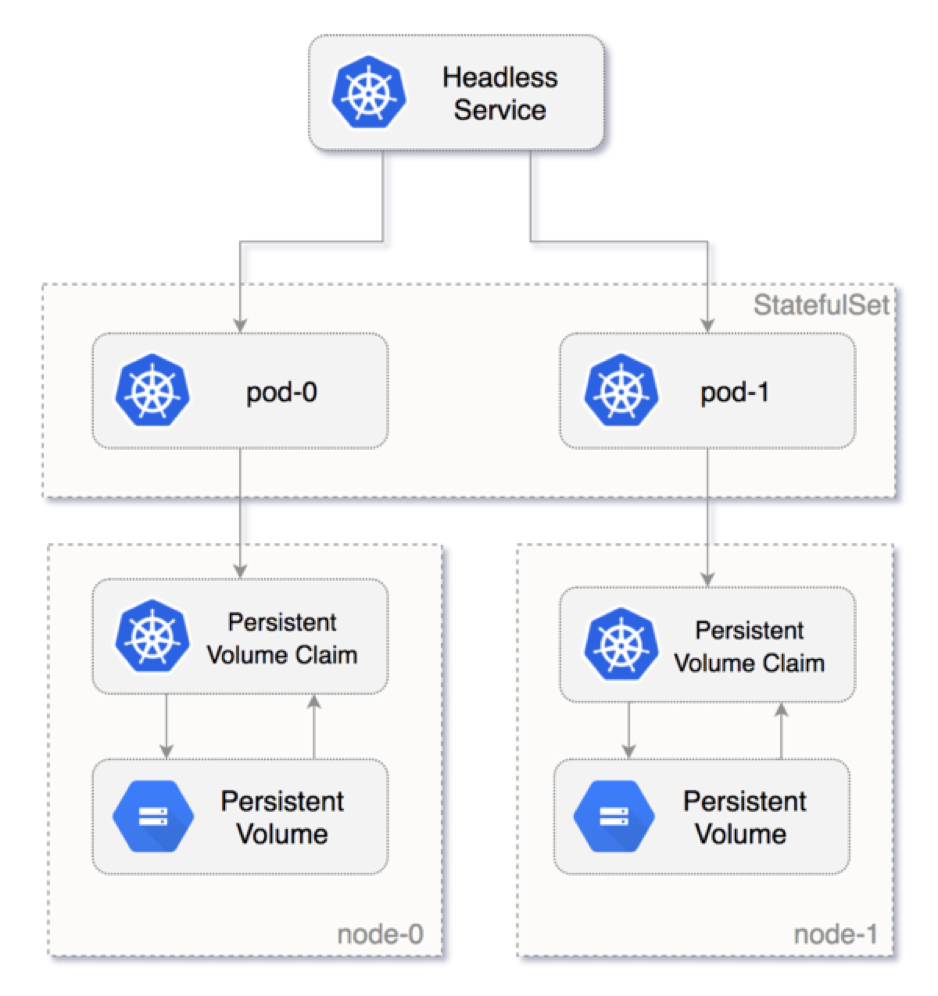
Key Reasons for Using a Headless Service:
1. Unique Hostnames:
Each pod gets a stable DNS name (e.g., mysql-0, mysql-1) for consistent access.
2. Direct Access:
Allows each pod to be accessed directly without load balancing, which is crucial for applications that need pod-to-pod communication (e.g., databases).
3. Service Discovery:
Provides DNS-based service discovery so each pod can be reached by its unique name, supporting clustering and persistent connections.
Example:
A headless service for a mysql StatefulSet might look like this:
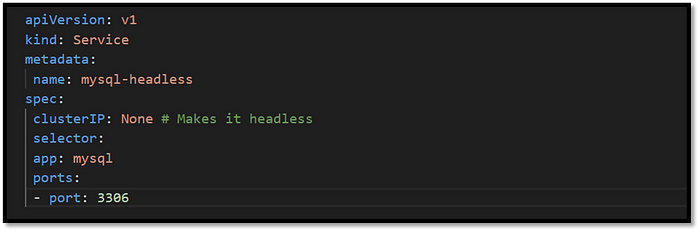
This setup ensures each mysql pod in the StatefulSet can communicate directly with others using stable hostnames, making it ideal for applications that need stateful coordination.
A key difference between Deployment and StatefulSet

Conclusion:
Kubernetes provides Deployments for managing stateless applications with features like rolling updates, scaling, and self-healing, while StatefulSets are designed for stateful applications requiring stable identities and persistent storage. Headless services ensure consistent communication for StatefulSets, making them ideal for databases and clustered systems.
If you can change your mind, you can change your life. — william james
Happy Learning!!!✨
